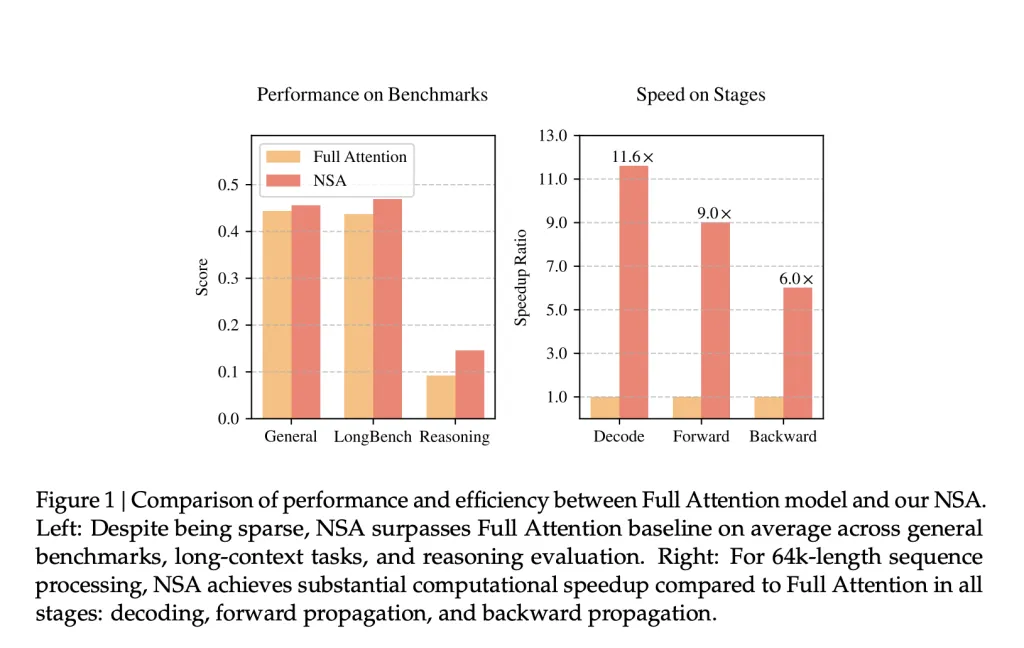
首页 › DEEPSEEK DeepSeek V4 曝光:下月发布,支持 100M 超长上下文,由国产芯片训练 2025-09-30 1 次阅读 会员专享 9月29日消息,今天下午 DeepSeek 突然推出了 DeepSeek v3.2-Exp 大模型。就在前几天刚刚发布 v3.1“终结版”后,DeepSeek 又迅速放出新动作,这也延续了其在重大节日前发布新模型的惯例。 相比性能提升,v3.2 更值得关注的其实是它所承载的技术探索。从“Exp”后缀就能看出,这一版本并非主打通用能力,而是用于验证新技术。 其中最亮眼的创新是 DeepSeek Sparse Attention(DSA)。它首次实现了细粒度稀疏注意力机制,在几乎不损失输出质量的前提下,大幅提升了长文本训练和推理的效率。 总体来说,v3.2 属于小幅度技术迭代。大家最期待的,仍然是传闻已久的 DeepSeek v4 及 r2 —— 尤其是 v4 这一基座级大模型。 近期有消息称,DeepSeek V4 将在 10 月发布,亮点包括: 100M 上下文(百万级别长文本处理能力) GRPO 驱动推理 NSA/SPCT 等新技术 数学、编程能力显著增强 推理速度更快、成本更低 这一爆料来自推特账号 “DeepSeek News C... 🔒 登录后继续阅读 登录账号即可免费阅读本文 立即登录 还没账户? 注册 相关推荐 DeepSeek V3.1 和 Claude Opus4.1 、GPT-5 编程挑战题目!及生成的提示词 2025-08-22 1 最新爆料:DeepSeek R2 即将发布!成本比GPT-4o暴跌 97% 2025-04-29 1 DeepSeek 重磅推出 NSA 功能!处理长文本、编写长篇故事更强 2025-02-19 1 DeepSeek R1 和 ChatGPT 各出狠招,这场PK太炸裂! 2025-02-12 2